
Title : MS 5118
Place : Avag Vankʻ (Cilicia)
Century : 1412
Scribe : Ṛstakes Sebastatsi
Colophone : --------------------------------------------------------------------------------------------------------------------------------------------------------------
Read Transcript Download
Name: Աղքատ մսախորով և արծիւ
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Առիւծն ծեր հիւանդացեալ
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Առիւծն հիւանդացեալ և էշ առանց սրտի և ականջի
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Առիւծ սուտ հիւանդացեալ
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Առիւծ և գայլ և աղուես
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Առիւծ և թագաւորի աղջիկ
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Արտուտ թագաւոր թռչնոց
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Գայլագռաւ պանիր ի կտուցն և աղուես
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Թագաւոր և աւձ և որդի թագաւորի
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Թագաւոր և շուն և շուք
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Ժիժիք և մեղուք և մրջիմն
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Խաւսող և աղուես և շուն
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Կոզեռն և յաւանակ և խոզք
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName: Կրիայք և խեցգետին և արծիւ
- - - - - - - - - - - - - - - - - - - - - - Story origin link
learn moreName
information about the person
Reference link missing
Name
information about the person
Reference link missing
Name
information about the person
Reference link missing
Name
information about the person
Reference link missing
Name
information about the person
Reference link missing
Name
information about the person
Reference link missing
Name
information about the person
Reference link missing
Name
information about the person
Reference link missing
About the Aghvesagirk
The Aghvesagirk is a collection of anonymous fables written between
the 14th and 17th centuries, attributed to Vardan Aygektsi. Early in
his preaching career, Aygektsi composed the collection Armat Havato,
consisting of extracts from Armenian doctrinal-rhetorical literature
(13th century). His discourses often included fables and parables,
making them clearer and more impactful, thus founding the
fable-discourse genre in Armenian literature.
Collections compiled in later centuries included a variety of
sources: a large number of Aesop’s fables; several chapters from
Kalīla wa-Dimna; Persian and Arabic tales and novels; stories from
the Armenian version of the Physiologus; small groups of Barlaam and
Josaphat's parables; parables about the life of Alexander the Great;
Armenian folk tales and novels; stories of good and bad churchmen,
biblical narratives, and historical incidents.
The Aghvesagirk survives in at least 80 manuscripts held in
libraries throughout Europe and the Near East, including Yerevan,
Venice, Vienna, Paris, London, Oxford, Berlin, Saint Petersburg, and
Jerusalem. These collections of fables vary in the number of fables
they contain. The oldest collection preserved in the Matenadaran,
was copied in the 14th century (MS 5871). This manuscript contains
only seven fables and was scribed by Monk Karapet. The largest
collection, written in 1640 by scribe Mkrtichʻ Lehtsʻi, contains 187
fables (Matenadaran, MS 8376).
The name Aghvesagirk gained prominence in the 17th century,
following the publication by Voskan Yerevantsi titled Book of the
World and Mythology, which is Aghvesagirk in 1668 Amsterdam
(Marseille 1683; Etchmiadzin 1698). The 1894 edition by N. Marr
titled Collection of Vardan's Fables is particularly noteworthy for
its inclusion of 21 manuscripts.
The present edition of the Aghvesagirk is particularly notable for
its comprehensive scope, incorporating 56 manuscripts.

About the project
This edition was made possible thanks to the generous support of
the Austrian Academy of Sciences Foundation and the University
of Vienna, which funded the project from 20**-2024 (supervisor
prof. Tara L. Andrews). The project utilized the digital tools
and methodologies of
the Chronicle of Matthew of Edessa Online project
(https://editions.byzantini.st/ChronicleME/#/Home)
Founder

Ani Shahnazaryan has been as an adjunct lecturer at the American University of Armenia since 2021. Her research interests include Digital Humanities, text encoding and markup, cutting-edge technology of literary study and computer-aided stemmatological analysis. She was a postdoctoral fellow at the University of Vienna (2018-2019) and Free University of Berlin (2020). She has started launching the digital critical edition of Armenian Medieval Fables, used digital technologies by researchers of the University of Vienna.
Contributors

Tara L. Andrews has been Professor for Digital Humanities at the University of Vienna since 2016. She did her B.Sc. in Humanities and Engineering at MIT (1995–1999), followed by an M.Phil. (2003–2005) and D.Phil. (2006–2009) at the University of Oxford. She began to study aspects of the Aghvesagirk while preparing her M.Phil. thesis; this together with her doctoral work resulted in a 2016 monograph published by Brill. Tara's research interests include the history and historiography of the Christian Near East in the tenth to twelfth centuries, the application of computational and statistical methods for reconstruction of the copying history of ancient and medieval manuscripts (stemmatology), and reflection on the implications of employing digital media and computational methods in humanities contexts, all of which have figured in production of the present edition.

Anahit Safaryan did her BA in History (2009-2013) and MA in History (2013-2015) at Yerevan State University. She started her doctoral studies at the University of Bern (2015-2017), where she was also employed to work on the SNSF project. In 2017, together with the project itself, Anahit moved to the University of Vienna to continue her doctoral research, which focuses on the topic of the reception of the Aghvesagirk in the 17th and 18th centuries.

Schiwa Aliabadi-Pongratz has been employed as an application developer at the University of Vienna since 2018. She has several years of working experience in the field of electronic publishing in the private sector and found her way to Digital Humanities via her recent coursework in South Asian and Buddhist Studies. She is responsible for several tools and applications that were used in the preparation of the critical edition.
Other Contributors
Web Development

Gabriel Adamyan has a Bachelor's degree in Computer
Science from the American University of Armenia. He is
responsible for all aspects of the website development process,
including database creation, management, functionality tools,
data sorting, and visual elements.
Methods of edition
Digital workflow
This edition of the Aghvesagirk has been conceived and implemented with a fully digital workflow. Our implementation relies on two innovative strands of development. The first is a graph-based computational model for critical editions of texts that survive in multiple manuscript copies; more about this model can be found in its documentation. The second strand of development is the use of a "continuous integration" system for management and curation of the textual data, whose stages are described here.
Manuscript transcription
We have obtained digital images of most of the extant manuscripts; although we do not, generally speaking, have the rights to publish these, we have been able to use them as the basis of our transcriptions.
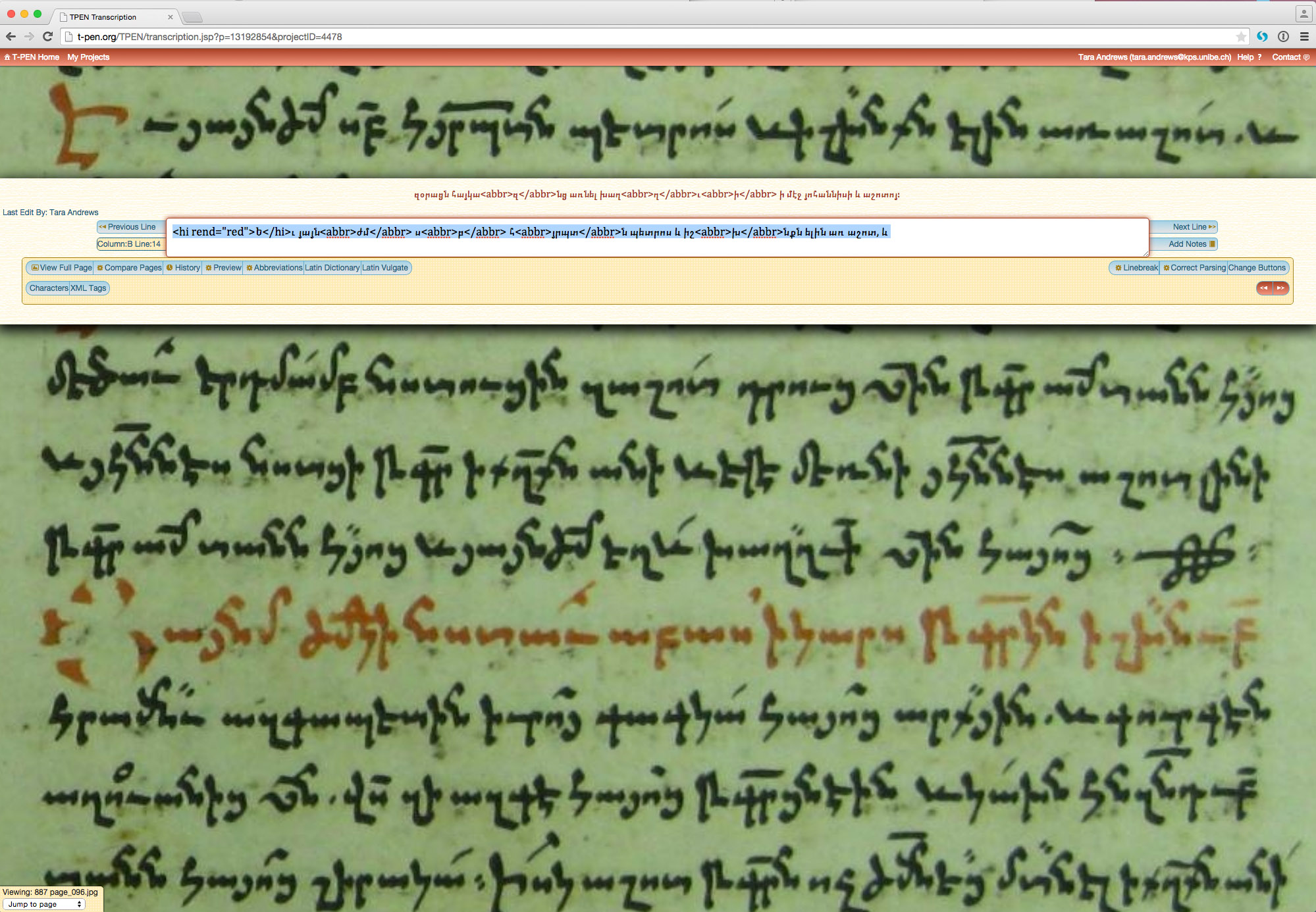
Transcription was done using T-PEN, a freely available online tool provided by the Center for Digital Theology at St. Louis University. Each line of text is associated with a region of a manuscript image; selected elements of the Text Encoding Initiative were used to capture certain features of the text. (For more information on the transcription, see the "Guidelines for transcription" below.)
The continuous integration pipeline

tpen-backup
Our pipeline process begins each day with export of the T-PEN data in
its native Shared Canvas JSON format.
tpen2tei
The next stage is to convert our transcription files to TEI-XML source
files using the tpen2tei Python library, which was developed within
the project. The transcriptions as they exist in T-PEN, together with
the custom transformations defined for the project for use with
tpen2tei, constitute the authoritative source of transcription
information. tpen-backup
Our pipeline process begins each day with export of the T-PEN data in
its native Shared Canvas JSON format.
tpen2tei
The next stage is to convert our transcription files to TEI-XML source
files using the tpen2tei Python library, which was developed within
the project. The transcriptions as they exist in T-PEN, together with
the custom transformations defined for the project for use with
tpen2tei, constitute the authoritative source of transcription
information.
validate-tei-xml
Whereas the tpen2tei step in the pipeline will detect and alert us to
any badly-formed XML output from our transcriptions (e.g. bad syntax
or mismatched element tags), it does not validate that XML against any
TEI schema. That task is done in the subsequent step. If any
transcription file is found to have invalid TEI encoding, the data
pipeline will stop at this point until the problem is found and fixed.
collate
Once transcribed, the manuscript texts have been collated with each
other, section-by-section, using the software CollateX. We also used
the collation to assist in the correct expansion of abbreviated words;
these abbreviations and expansions are stored in a separate database,
which is consulted for later collation runs in order to improve the
results.
feed-editions-moe
After segmentation into sections and collation, the results are loaded
into the Stemmaweb suite of tools for further processing.
Editorial work after the pipeline
Automated collation, although very good in most cases, is by no means
perfect. Each section, once it reached this point in the process, was
imported into the Stemmaweb suite of tools for further work. The
variant graph viewer within Stemmaweb allows corrections to be made to
the collation, and allows the association and classification of
individual variants. Manuscripts